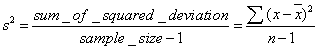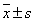Đường hồi quy (regression line) là đường thẳng mô tả mối tương quan tuyến tính giữa
hai biến. Phương trình đường hồi quy (regression equation) có thể dự đoán giá trị của biến kết quả y dựa
trên một giá trị của biến giải thích x cho sẵn:

Trong đó:
 (đọc là y-hat hay y mũ) là giá trị của y với x cho trước;
(đọc là y-hat hay y mũ) là giá trị của y với x cho trước;
a là giao điểm của đường hồi quy với trục tung
(y-intercept)
b là hệ số
góc, hay chính là lượng thay đổi của y khi x tăng lên một đơn vị, ta có:

Giá trị tuyệt
đối của b càng lớn thì đường hồi quy càng dốc.
Tương tự như
hệ số tương quan, dấu của hệ số góc cũng thể hiện chiều của tương quan:
- Nếu b >0 thì tương quan thuận
- Nếu b < thì tương quan nghịch
- Nếu b = 0 thì không có tương quan
Lưu ý: Trước
tiên ta vẽ biểu đồ tán xạ để xem hai biến có quan hệ tuyến tính hay không, nếu
có thì mới dùng các phần mềm thống kê để tính toán các chỉ số a và b để từ đó
thiết lập phương trình hồi quy.
Phần dư
(residuals) là khoảng khác biệt giữa giá trị của y dự đoán bởi phương trình hồi
quy
so với giá trị thực tế
của y. Trên biểu đồ tán xạ, phần dư được thể hiện bẳng một đường thẳng nối từ
điểm  trên đường hồi quy đến
điểm
trên đường hồi quy đến
điểm  .
.
trên đường hồi quy đến
điểm .- Phần dư
dương nếu y thực tế (
) lớn hơn y dự đoán (
- Phần dư âm nếu
- Phần dư bằng
0 nếu
Phần mềm thống
kê có thể giúp ta tính phần dư của mỗi quan sát trong toàn bộ dữ liệu. Ta có thể
dễ dàng tìm thấy những phần dư có giá trị đặc biệt lớn bằng cách vẽ biểu đồ tần
số (vd như histogram).
Phương pháp
bình phương nhỏ nhất (Least Squares
Method) là một cách thức đơn giản mà các phần mềm thống kê dùng để tính
phương trình đường hồi quy mà trong đó máy tính sẽ tìm ra trong số rất nhiều đường
thẳng có thể để chọn lấy đường thẳng có tổng bình phương phần dư nhỏ nhất và có
dạng
để dự đoán giá trị của
y một cách gần đúng nhất.

Tính chất của
đường hồi quy:
- Vì có phần dư dương lẫn âm nên tổng (và trung bình cộng) của các phần dư bằng 0.
- Đường hồi
quy đi qua điểm giữa của dữ liệu
(với
và
là giá trị trung bình của x và y)
Gọi  và
và  là độ lệch chuẩn của x và y, ta có:
là độ lệch chuẩn của x và y, ta có:
và là độ lệch chuẩn của x và y, ta có:
Hệ số góc : 
y-intercept : 
So sánh hệ số góc và hệ số tương quan:
Giống nhau :Đều được dùng để chỉ mối
tương quan tuyến tính và cùng dấu với nhau (âm, dương hoặc bằng 0)
Khác nhau :
- Hệ số tương quan dao động từ -1 đến +1 còn hệ số góc có thể nhận giá trị bất kì.
- Đường hồi quy dự đoán giá trị của y theo x và đường hồi quy dự đoán giá trị của x theo y sẽ có phương trình khác nhau (hệ số góc khác nhau) còn hệ số tương quan giữ nguyên khi có sự thay đổi vai trò này giữa x và y.
- Hệ số góc và y-intercept thay đổi theo đơn vị của x còn hệ số tương quan thì không.

 và
và  lần lượt là z-score của
x và y, ta có công thức tính r như sau :
lần lượt là z-score của
x và y, ta có công thức tính r như sau :


 là giá
trị trung bình và s là độ lệch chuẩn của x so với
là giá
trị trung bình và s là độ lệch chuẩn của x so với