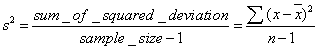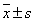Ngoài các tham số như giá trị trung bình và trung vị để đo
lường khuynh hướng trung tâm hay độ lệch chuẩn để đo lường tính biến thiên, người
ta còn dùng các tham số chỉ vị trí của phân bố. Một vài ví dụ về tham số chỉ vị
trí như trung vị (median)- điểm giữa của phân bố; min-max, giá trị nhỏ và lớn
nhất của phân bố hoặc z-score- đại lượng cho biết một quan sát lệch khỏi giá trị
trung bình bao nhiêu lần độ lệch chuẩn.
Trung vị thực chất là trường hợp đặc biệt của tham số chỉ vị
trí có tên gọi là bách phân vị
(percentiles). Bách phân vị thứ p (pth
percentile) là vị trí có p phần trăm trên tổng số quan sát nhận giá trị nhỏ
hơn hoặc bằng giá trị tại điểm đó ( với điều kiện dữ liệu đã được sắp xếp theo
thứ tự từ nhỏ đến lớn). Trung vị là giá trị giữa của quan sát, vì vậy ta còn gọi
trung vị là bách phân vị thứ 50 (50th percentile), nghĩa là có 50% tổng
số quan sát nhận giá trị nhỏ hơn hoặc bằng giá trị tại điểm bách phân vị thứ
50.

Một dạng đặc
biệt của bách phân vị đó là tứ phân vị (quartiles). Có 3 tứ phân vị:
- Tứ phân vị thứ nhất (first quartile, Q1) tương ứng với bách phân vị thứ 25 (25th percentile).
- Tứ phân vị thứ hai (second quartile, Q2, hay median) tương ứng với bách phân vị thứ 50 (50th percentile).
- Tứ phân vị thứ ba (third quartile, Q3) tương ứng với bách phân vị thứ 75 (75th percentile).

Tứ phân vị
được xác định như sau:
- Sắp xếp dữ liệu theo thứ tự tăng dần
- Tìm trung vị, đây là Q2
- Tìm trung vị của dãy số ở dưới Q2 (lưu ý nếu tổng số quan sát là số lẻ thì không tính trung vị trong khoảng này), đây là Q1
- Tìm trung vị của dãy số ở trên Q2 (lưu ý nếu tổng số quan sát là số lẻ thì không tính trung vị trong khoảng này), đây là Q3
Công thức tính: IQR= Q3-Q1

Một phương pháp xác định giá trị ngoại biên
(potential outlier):
Ta gọi:
- L (tức lower) là giá trị thấp của biến, L = Q1 – 1,5xIQR
- U (tức upper) là giá trị cao của biến, U = Q3 + 1,5xIQR
- Kết luận: Nếu trong dãy số có số nào thấp hơn L hay cao hơn U thì có thể xem đó là outlier.